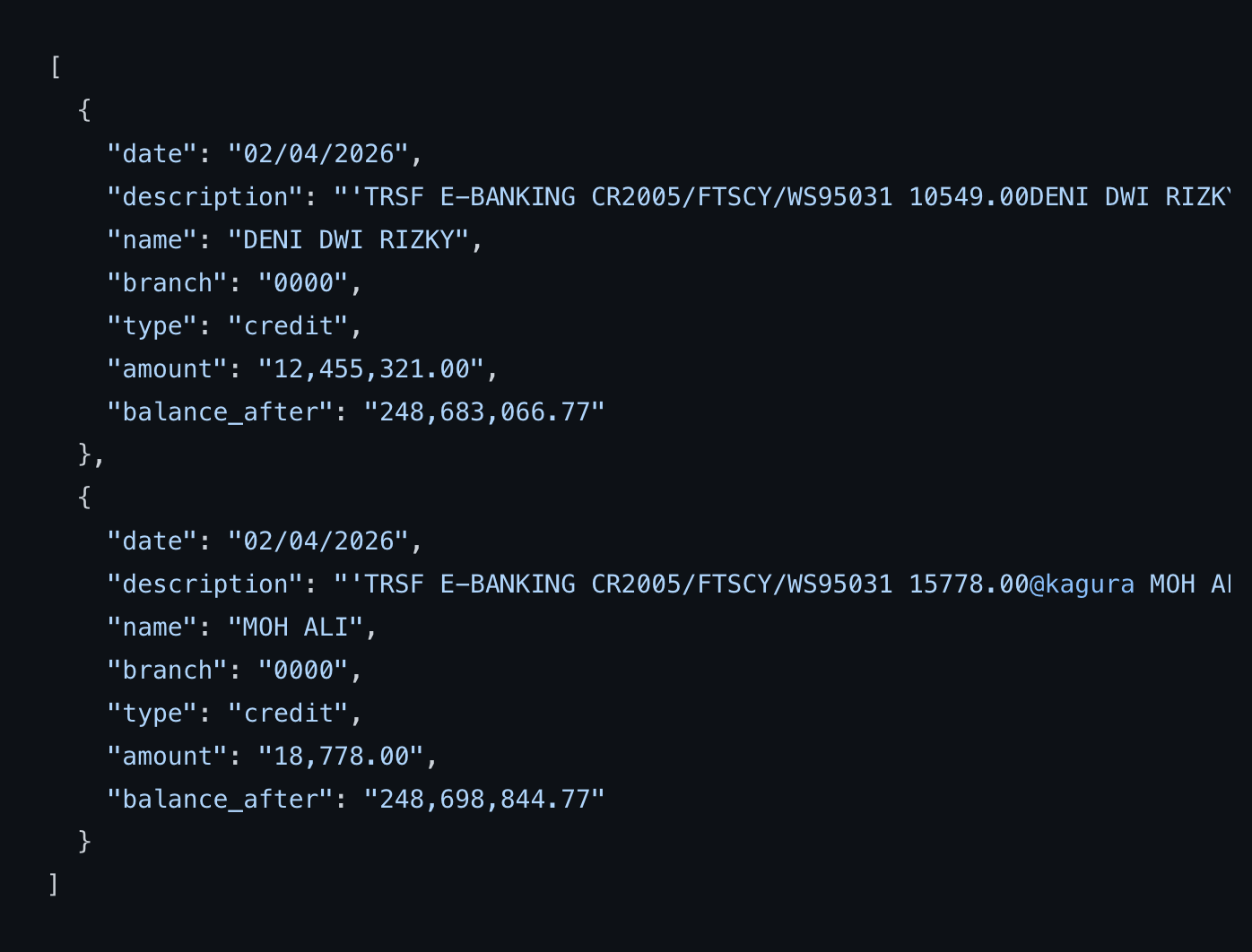
This source code provides a fully automated solution for checking BCA Personal (iBank) account mutations without manual verification. Built with Node.js and Playwright, the system performs scheduled scraping of incoming transactions at configurable intervals — tested stable at every 5 minutes — making it ideal for businesses that require real-time payment validation at scale.
Unlike solutions built on Puppeteer, this tool leverages Playwright as its core engine, delivering better stability, lower resource consumption, and native support for headless execution on Linux via Xvfb. The system supports browser rotation across Chromium, Google Chrome, Microsoft Edge, and Brave, combined with automatic User-Agent rotation to maintain scraping consistency and minimize detection risk.
Each detected transaction is automatically pushed to your configured webhook endpoint in structured JSON format — including transaction date, sender name, branch code, transaction type, amount, and post-transaction balance. This makes it straightforward to integrate with any existing payment system, deposit automation pipeline, or internal back-office application without additional data transformation.
The auto login and auto logout mechanism ensures session integrity across long-running deployments, reducing the risk of session timeout or login failure that commonly affects automation systems operating on banking platforms. Optional proxy support with automatic rotation is also included for deployments that require IP diversity or operate in restricted network environments.
Who This Product Is Built For
This BCA mutation scraper is designed for developers and businesses who need reliable, automated transaction monitoring without depending on official banking APIs. Whether you are running a digital goods platform, a top-up service, or an internal finance automation system, this tool gives you the infrastructure to detect and process incoming payments in near real-time.
If you operate a deposit-based platform where users fund their accounts via bank transfer, manually checking mutations is simply not scalable. Every missed transaction means a delayed order, a frustrated customer, and additional support overhead. This source code eliminates that bottleneck entirely by automating the detection and forwarding of every incoming transaction to your system the moment it is confirmed.
Game top-up platforms benefit significantly from this kind of automation. When a user sends a payment via BCA transfer, the system detects the transaction, extracts the sender name and amount, and pushes the data to your backend via webhook — allowing your platform to credit the user's account and process the order automatically, without any human intervention.
PPOB operators and SMM panel owners face a similar challenge. High transaction volume means manual mutation checking is not just inefficient — it is practically impossible. This scraper runs continuously in the background, ensuring every incoming payment is captured and forwarded regardless of transaction volume or time of day.
Fintech developers building internal tools, lending platforms, or digital wallet systems will also find this source code useful as a foundation for building more complex payment verification workflows. Because the entire codebase is exposed and customizable, you are not locked into a fixed feature set — you can extend, modify, and adapt the logic to fit your specific requirements.
How the Automation Works
The system initializes a browser session using Playwright and navigates to the BCA Personal iBank portal. After authenticating with the credentials you configure, it reads the mutation list and extracts transaction data from the current session. The extracted data is then normalized into a clean JSON structure and dispatched to your webhook endpoint.
Between each scraping cycle, the system performs an auto logout to cleanly terminate the session, followed by a wait period before the next login. This approach reduces the likelihood of triggering security alerts associated with persistent or unusual session behavior. The browser and User-Agent rotation further diversifies the request fingerprint across scraping cycles.
On Linux servers, the system runs in headless mode via Xvfb, meaning no graphical interface is required. This makes it fully compatible with VPS deployments, cloud servers, and containerized environments. On Windows, the browser runs normally without additional configuration. Both platforms are supported out of the box, and the installation documentation covers both environments in detail.
Technical Architecture and Stack
The core runtime is Node.js version 16 or higher, chosen for its event-driven architecture and strong ecosystem support for automation and webhook-based workflows. Playwright serves as the browser automation layer, providing a more modern and stable API compared to Puppeteer, with built-in support for multiple browser engines and improved handling of dynamic web content.
The webhook handler is implemented as a straightforward HTTP POST dispatcher, sending the transaction payload to any endpoint you specify in the configuration. This design is intentionally agnostic — it works with Laravel webhook receivers, Express.js handlers, Python Flask endpoints, or any HTTP server capable of accepting a POST request with a JSON body.
Proxy configuration is optional and handled through a list file. When a proxy list is provided, the system rotates through the available proxies automatically, assigning a different proxy to each browser session. This is particularly useful for deployments where the server IP has been flagged or where geographic diversity is required for stability.
Integration Examples
For a Laravel-based deposit system, the typical integration involves setting up a webhook route that receives the JSON payload, validates the transaction data, and triggers the appropriate deposit logic for matching user accounts. The sender name and amount fields from the mutation output are usually sufficient to match against pending deposit records.
For a Node.js backend, the integration is even more direct — you can run the scraper and the webhook receiver within the same Node.js environment, or deploy them as separate services communicating over HTTP. The JSON output format is clean and consistent, making it easy to parse and process without additional normalization.
For teams using Python-based backends, the webhook endpoint can be implemented using Flask or FastAPI, with the transaction data deserialized from the JSON payload and processed according to your business logic.
Customization and Support
The source code is fully open for modification. Buyers regularly customize the output fields, adjust the scraping interval, extend the webhook payload with additional metadata, or integrate the scraper into larger automation pipelines. The codebase is structured to be readable and maintainable, making it approachable even for developers who are new to Playwright or browser automation.
If you require customization beyond what you can implement yourself — such as building a full dashboard on top of the scraper, integrating it with a specific payment gateway, or adapting it for a multi-account setup — paid customization services are available. You can reach out via WhatsApp to discuss your requirements and get a quote before committing.
Lifetime minor updates are included with every purchase. This means that when BCA updates the iBank interface and the scraper breaks, you will receive a fix at no additional cost. Major architectural updates are covered for up to three months from the date of purchase. Technical support for installation and configuration issues is available via WhatsApp throughout the support period.
Why Choose Aditdev.ID
Every product sold through the Aditdev.ID marketplace is built and maintained by Aditama Gilang Farel, an Indonesia-based full-stack developer with over 10 years of hands-on experience in web application development, automation engineering, and scraping systems. This is not a resold or repackaged script — it is a product that has been actively used, tested, and iterated on based on real-world deployment feedback.
The BCA mutation scraper has been running in production environments since its initial release in mid-2024, with multiple major and minor updates addressing interface changes, stability improvements, and feature additions based on buyer requests. The migration from Puppeteer to Playwright in version 2.0 represents a significant architectural improvement that meaningfully improves performance and reduces resource usage in long-running deployments.
Aditdev.ID specialises in building digital infrastructure for businesses operating in the Indonesian market — including SMM panels, game top-up platforms, PPOB systems, fintech applications, deposit-based services, and SaaS products. The tools and source code available in the store reflect the kinds of problems that real Indonesian digital businesses face every day, built by someone who has solved those problems repeatedly across different client projects.
Understanding BCA iBank Mutation Scraping for Payment Automation
Bank Central Asia, commonly known as BCA, remains one of the most widely used banks for digital transactions in Indonesia. For businesses that accept BCA transfers as a payment method, monitoring incoming mutations is a critical part of daily operations. The BCA Personal iBank platform, accessible at ibank.klikbca.co.id, provides individual account holders with access to their transaction history — but without an official public API, developers who need programmatic access to this data must rely on browser automation to retrieve it.
This is precisely the problem that this source code solves. By automating the login, mutation retrieval, and logout process using Playwright, the system gives developers and business owners access to structured transaction data on a recurring schedule — without requiring any manual interaction with the iBank interface.
The absence of an official BCA Personal API for third-party use is a well-known limitation in the Indonesian developer community. While BCA does offer a corporate API product for enterprise clients, it is not accessible to individual developers or small businesses without going through a formal and often costly onboarding process. Browser-based automation has therefore become the practical standard for independent developers building deposit systems, payment validators, and financial automation tools that rely on BCA Personal accounts.
Common Use Cases in the Indonesian Digital Economy
The Indonesian digital economy has grown rapidly over the past decade, with a significant portion of online transactions still conducted via direct bank transfer rather than card payments or e-wallets. This makes real-time mutation monitoring particularly important for a wide range of business types.
Digital goods and services platforms — including gaming top-up websites, streaming account resellers, and software license stores — typically require users to make a bank transfer and then confirm their payment manually. Without automation, the seller must periodically log in to iBank, check the mutation list, and manually match each incoming transaction to a pending order. This process does not scale and introduces significant delays during peak transaction periods.
Automated deposit systems eliminate this friction entirely. When a user initiates a transfer, the scraper detects the incoming mutation within the next scheduled interval, extracts the transaction details, and sends them to the platform backend via webhook. The backend then matches the transaction to a pending order based on amount and sender name, credits the user's account, and fulfills the order — all without any human intervention.
PPOB (Payment Point Online Bank) operators face a similar operational challenge. PPOB platforms process high volumes of bill payment transactions on behalf of customers, and many of these platforms use BCA Personal accounts as collection accounts for customer deposits. Automating the mutation check ensures that customer balances are updated promptly and accurately, reducing the support burden associated with delayed or undetected payments.
SMM panel operators — who provide social media marketing services such as followers, likes, and engagement metrics — operate in a similarly high-volume transaction environment. Their customers deposit funds before placing orders, and any delay in deposit confirmation directly impacts order processing speed. The BCA mutation scraper ensures that deposits are detected and credited as quickly as the scraping interval allows.
Fintech developers building internal tools for financial monitoring, cash flow tracking, or payment reconciliation will also find this source code useful as a foundation. The structured JSON output provides a clean data layer that can be consumed by analytics dashboards, accounting systems, or notification services with minimal additional development effort.
Deployment Considerations and Best Practices
When deploying this scraper in a production environment, several factors should be considered to ensure stable and consistent operation over time.
Server selection matters. A Linux VPS with at least 1GB of RAM is recommended for stable Playwright execution with Xvfb. Lower-memory instances may experience instability during browser initialization, particularly when running alongside other services. A dedicated low-cost VPS from providers such as DigitalOcean, Vultr, Hetzner, or local Indonesian providers is typically sufficient for single-account deployments.
Session management is handled automatically by the auto login and auto logout cycle, but it is still worth configuring the scraping interval conservatively when first deploying. Starting with a 10-minute interval and reducing to 5 minutes after confirming stable operation is a reasonable approach. Extremely short intervals — under 3 minutes — are not recommended and may trigger rate limiting or unusual activity flags on the iBank platform.
Webhook reliability should also be considered. If your webhook endpoint is unavailable when the scraper attempts to dispatch a transaction, the data will not be automatically retried by default. Depending on your use case, you may want to implement a local queue or retry mechanism in your webhook receiver to handle transient failures gracefully.
Proxy usage is optional but recommended for deployments where the server IP address is shared with other automated traffic or where previous scraping activity may have resulted in IP-level friction. The built-in proxy rotation handles this automatically when a proxy list is provided, cycling through available proxies across sessions.
Extending the Source Code
Because the source code is fully exposed and written in straightforward Node.js, it is well-suited for extension by developers with varying levels of experience. Common extensions that buyers have implemented include multi-account support, where the scraper cycles through multiple iBank accounts and aggregates mutations from each into a unified webhook stream. This is particularly useful for platforms that use multiple collection accounts to distribute incoming transaction volume.
Another common extension is adding a local database layer — typically SQLite or MySQL — to persist transaction records between scraping cycles. This allows the system to detect and skip duplicate transactions even if the webhook endpoint was temporarily unavailable during a previous cycle, and provides a local audit trail of all detected mutations.
Dashboard integration is another popular extension. By combining this scraper with a simple Laravel or Next.js admin panel, operators can visualize incoming transactions, filter by date or amount, and manually trigger reprocessing of specific transactions when needed. The Scraper plus Dashboard package available through Aditdev.ID provides a ready-built version of this setup for buyers who prefer not to build the dashboard layer themselves.
Notification integration is straightforward given the webhook architecture. By routing webhook events through a notification dispatcher, you can send Telegram messages, WhatsApp alerts, or email notifications for every incoming transaction above a specified threshold — useful for monitoring high-value payments or detecting unusual activity in real time.
Frequently Asked Questions from Developers
Developers evaluating this product commonly ask whether the scraper can handle OTP or two-factor authentication prompts during login. The current implementation is designed for standard iBank login flows and does not include automatic OTP handling. If your account is configured to require OTP on every login, additional customization will be needed to handle the authentication step.
Another common question concerns rate limits and detection avoidance. The browser and User-Agent rotation included in the source code provides a reasonable level of fingerprint diversity, but no scraping tool can guarantee zero detection risk when operating against a banking platform. Using the tool responsibly — with conservative intervals, proxy rotation where appropriate, and a genuine business account — minimizes this risk significantly.
Developers also ask whether the scraper can be containerized using Docker. While Docker deployment is not covered in the included documentation, Playwright-based Node.js applications are generally well-suited for containerization. The main consideration is ensuring that the Xvfb dependency is correctly configured within the container image, which requires a base image with the necessary display libraries installed.
Finally, many buyers ask about the possibility of extending the scraper to support BCA Business or KlikBCA Bisnis accounts in addition to the Personal iBank platform. These platforms have different interface structures and authentication flows, and are not currently supported by this source code. Support for additional BCA account types may be considered in future major releases or can be requested as a custom development project through Aditdev.ID's consultation service.
Why Node.js and Playwright Are the Right Choice for Banking Automation
When selecting a technology stack for browser-based automation against complex web applications like iBank, the choice of runtime and automation library has a direct impact on long-term reliability. Node.js provides an event-driven, non-blocking execution model that is well-suited for scheduling recurring tasks, handling asynchronous webhook dispatches, and managing browser lifecycle events without blocking the main thread.
Playwright, developed and maintained by Microsoft, represents the current state of the art in browser automation. Compared to its predecessor Puppeteer, Playwright offers native support for multiple browser engines — Chromium, Firefox, and WebKit — from a single API. It provides more robust handling of network interception, improved support for dynamic JavaScript-rendered content, and a more mature approach to browser context isolation. For scraping tasks that require consistent behavior across long-running deployments, these characteristics translate directly into fewer unexpected failures and less maintenance overhead.
The decision to migrate this source code from Puppeteer to Playwright in version 2.0 was driven by real-world stability issues observed in production deployments running the v1.x series. Memory leaks under prolonged operation, inconsistent behavior during page transitions, and limited headless support on Linux were the primary pain points that Playwright addresses more effectively. Buyers upgrading from v1.x to v2.0 consistently reported improvements in uptime and a reduction in manual intervention required to keep the scraper running.
Security Considerations When Running Financial Automation Tools
Running automated tools against a banking platform introduces a set of security responsibilities that buyers should take seriously. The most important is credential management — your iBank username and password should be stored in environment variables or a secrets manager, never hardcoded in the source files or committed to a version control repository. The source code is structured to read credentials from environment configuration, making it straightforward to follow this best practice from the start.
Network security is another consideration. If you are running the scraper on a shared VPS or cloud instance, ensure that the webhook endpoint receiving transaction data is served over HTTPS and implements at minimum a shared secret or token-based authentication to prevent unauthorized parties from injecting fake transaction events into your system.
Finally, access to the server running the scraper should be restricted to authorized personnel only. Because the scraper has authenticated access to a live bank account, any compromise of the server environment could expose sensitive financial information. Standard server hardening practices — SSH key authentication, firewall rules, and regular security updates — apply here as they would for any production service handling sensitive data.
Aditdev.ID provides this source code as a tool for legitimate business automation, and buyers are responsible for ensuring their use complies with applicable terms of service and regulations. The disclaimer included with the product exists to set clear expectations about the nature of browser automation against banking platforms and the responsibilities that come with operating such tools in a production environment.